kcore started as a single-controller system. One controller, one SQLite database, one source of truth. That works fine when you have a handful of nodes in a single rack. It stops working when you need the control plane to survive a controller going down, or when you want to run controllers in two different datacenters.
Most people solving this problem reach for Raft. etcd uses it, CockroachDB uses it, Consul uses it. It's the standard answer. We went a different way: CRDTs — Conflict-free Replicated Data Types. Here's why.
The problem with consensus across datacenters
Raft gives you strong consistency. Every write goes through a leader, gets replicated to a majority of nodes, and only then is acknowledged. This is great within a single datacenter where round-trip times are sub-millisecond. It's terrible across datacenters.
If your Raft cluster spans DC1 in London and DC2 in Frankfurt, every write now pays a 10-20ms cross-DC round trip — not for the actual work, but just to reach consensus. Worse: if the link between DCs goes down, the minority side can't accept writes at all. Your control plane in DC2 becomes read-only or fully unavailable, even though the local machines are perfectly healthy.
For a hypervisor control plane, that's unacceptable. If DC2 loses connectivity to DC1, the operator in DC2 should still be able to create VMs, stop VMs, and manage their local nodes. The world doesn't stop because a fiber got cut.
What CRDTs actually give you
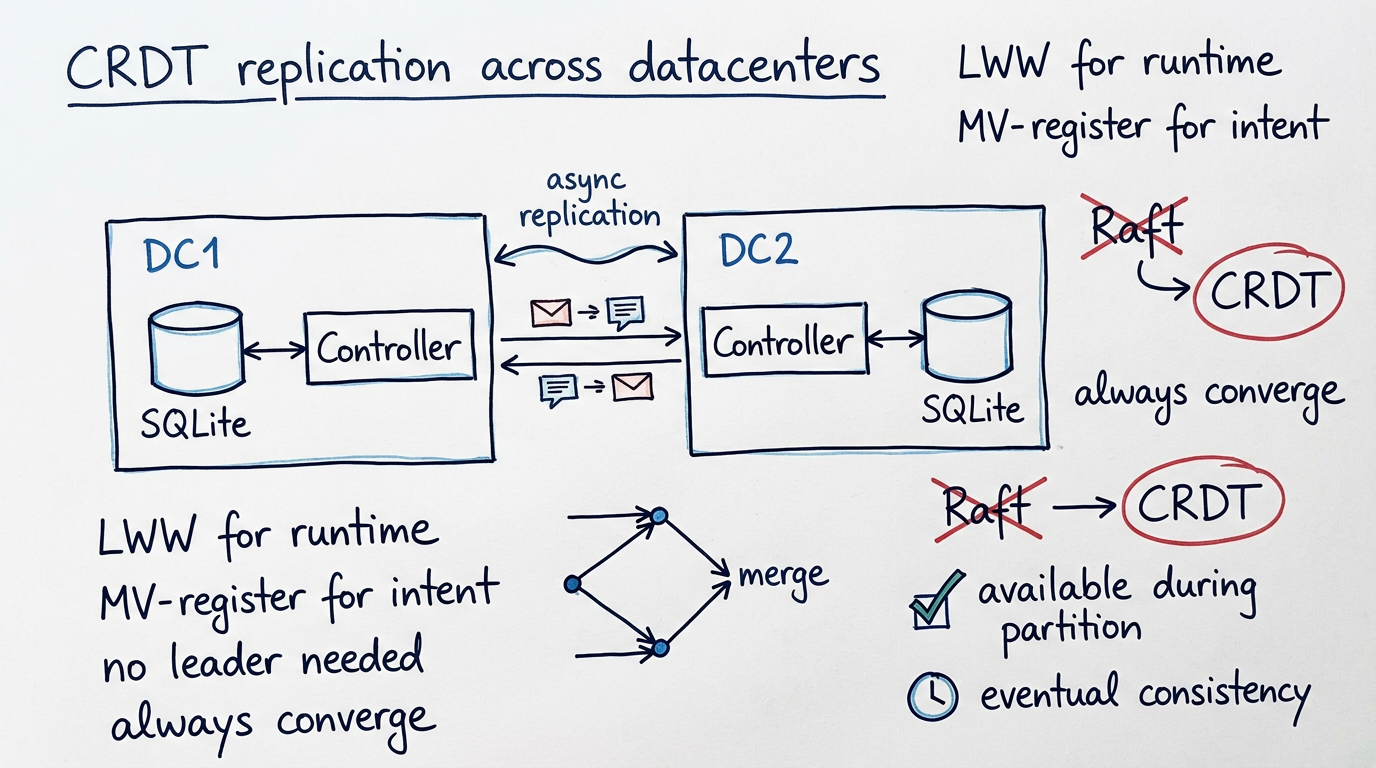
A CRDT is a data structure where any two replicas can be merged without coordination and the result is always correct. No leader election, no majority quorum, no blocking on remote nodes. Each controller writes to its own local SQLite, and changes propagate to peers asynchronously. When they arrive, they merge deterministically.
The key insight is that merge must be commutative, associative, and idempotent. If controller A and controller B both make changes while disconnected, when they reconnect, the merge of A's state into B gives the same result as merging B's state into A. Order doesn't matter. Duplicates don't matter. You always converge.
kcore's hybrid CRDT model
Not all data in a hypervisor control plane has the same consistency requirements. A VM's runtime state (running, stopped, CPU usage) is fundamentally different from a VM's desired specification (how many cores, which image, which network). We use different CRDT strategies for each.
Runtime/observational state uses Last-Writer-Wins (LWW) registers. Node heartbeats, VM runtime status, last-seen timestamps — these fields naturally represent the latest observation. If two controllers both receive a heartbeat from the same node, the most recent one wins. Simple, correct, zero conflicts.
Desired/declarative state uses an OR-Map with multi-value registers. VM specs, network configs, SSH keys, labels — these represent operator intent. If two operators concurrently modify the same VM from different controllers, we don't silently drop one edit. Both values are preserved as a conflict that the operator can see and resolve. This is the same approach Riak used, and it's the only honest thing to do when you give up linearizability.
Deletes use tombstones with causal metadata. A tombstone isn't garbage-collected until all known peers have acknowledged seeing it. This prevents the classic "delete resurrection" problem where a peer that hasn't seen the delete re-introduces the deleted record.
How replication works in practice
Each kcore controller keeps its own SQLite database plus a replication log — an append-only table of mutation events with causal metadata. When a controller processes a write (create VM, register node, update network), it appends the event to its replication log and fans it out to peers over gRPC.
Peers receive events, apply CRDT merge rules, and acknowledge up to a frontier. The sending controller tracks the acknowledgement frontier per peer, so it knows which events have been seen and which haven't.
This realtime path handles the happy case. For the unhappy case — a peer was down for hours, the log was compacted, or events were lost — there's a periodic anti-entropy reconciler. It runs as a background task, compares frontiers with each peer, pulls missing event ranges, and falls back to a full snapshot sync if the gap is too large.
Why this matters for multi-DC
In a two-DC setup, the topology looks like this: DC1 has one or more controllers, DC2 has one or more controllers, and they replicate across the WAN. Under normal conditions, replication lag is the WAN round-trip time — maybe 10-20ms between European cities, 50-100ms intercontinental.
When the inter-DC link goes down, both sides keep operating independently. Operators in DC1 create VMs, operators in DC2 create VMs. When the link comes back, the anti-entropy reconciler catches up and merges everything. If there are conflicts (two operators modified the same VM spec), they surface as explicit multi-value conflicts that the operator resolves.
With Raft, one side would have been frozen. With CRDTs, both sides stayed productive. The cost is that you might occasionally need to resolve a conflict — but in practice, concurrent edits to the same VM from different DCs are rare. The common case (creating different VMs, heartbeats, status updates) merges without any conflicts at all.
The scheduler under eventual consistency
The trickiest part isn't replication itself — it's the scheduler. When a controller places a VM on a node, it reads the node's capacity and current load from its local replica. That data might be slightly stale. The node might already be at capacity from a placement made by another controller that hasn't replicated yet.
We handle this with commit-time validation. The scheduler makes a placement decision based on its local view, but the node-agent rejects the apply if the actual resources don't match. The controller then retries with a fresh view. It's optimistic concurrency control, the same pattern databases have used for decades. In practice, conflicts are rare because capacity headroom is usually large relative to individual VM size.
SQLite stays
A common reaction to "we need replication" is "time to switch to Postgres" or "let's use etcd." We didn't. Each controller keeps its own SQLite database. Replication happens at the application level through the CRDT event log, not at the storage level.
This is a deliberate choice. SQLite is fast, requires zero operational overhead, and is the perfect fit for a control plane that manages tens to hundreds of nodes. Adding a separate database cluster would double the operational complexity for zero benefit at this scale. The CRDT layer gives us the replication semantics we need without giving up SQLite's simplicity.
Verifying correctness with TLA+
Distributed protocols are notoriously hard to get right. The kind of bugs you find — lost deletes, state resurrection after partition heal, divergent replicas that never converge — don't show up in unit tests. They show up at 3 AM when two datacenters reconnect after a 4-hour partition.
We're using TLA+ to model the replication protocol before fully committing to the implementation. The spec covers controller-to-controller replication convergence, cross-DC eventual consistency under partition and rejoin, and the guarantee that no VM desired state is orphaned after a controller crash. If the model checker finds a violation, we fix the protocol design before writing Rust code — not after a customer hits it in production.
The honest tradeoffs
CRDTs aren't free. You give up linearizability — two controllers might briefly disagree about the current state of the world. You need a conflict resolution UX for the rare case where concurrent edits collide. Tombstones accumulate metadata that needs periodic compaction. Debugging replication issues is harder than debugging a single-writer database.
For kcore, these tradeoffs are right. A hypervisor control plane must stay available during network partitions — operators need to manage their local VMs even when the WAN is down. Occasional conflicts on concurrent edits are a small price to pay for a control plane that never goes read-only because it lost quorum.
The replication infrastructure is being built incrementally. Phase 1 (multi-controller topology and failover) is already in place. Phase 2 (the CRDT event log and merge engine) is in progress. We'll write more about the implementation details as they land.